Reaktive HttpServer
When monolithic applications are decomposed into microservices, the architecture must rely on network protocols to communicate between the distributed components. Therefore, when scaling microservices it is necessary to scale the entire application stack of networking protocols and microservices logic.
The Reaktivity Project uses shared memory streams to directly communicate between each different layer in the application stack, including both the networking protocols and the microservices logic. Parallel execution of each layer in the application stack takes full advantage of the available CPU cores to maximize throughput with predictably low latency.
Recognizing that large systems can have 1000s of CPU cores, this technology can be deployed economically in the cloud to provide affordable real-time solutions.
Status Quo
The built-in Java HttpServer bundled since JDK6 provides a simple application stack to support HTTP and HTTPS microservices.
Despite using non-blocking IO, the built-in Java HttpServer in JDK8 still attempts to scale up by allocating a thread per connection. Other implementations of the same application stack scale up more efficiently by using non-blocking IO to handle multiple connections per thread.
However, in both scenarios the entire application stack is executed on the same thread to process an HTTP request. When multiple HTTP requests are being processed in parallel, each thread executes all layers of the application stack, as shown in the diagram below.
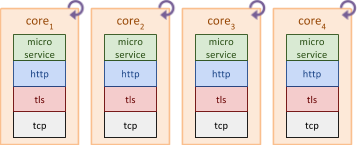
Each CPU core has a deep execution stack through the TCP, TLS, HTTP and microservice layers, creating round-trips internally in the code, as the stack for each HTTP request processing must unwind back to the TCP layer before detecting that more data is available on the network.
Drawing a comparison to network protocol design, where the client and server endpoints may be geographically quite distant, round-trips in those underlying protocols can easily lead to lengthy delays and a poor user experience because the endpoints must wait for each roundtrip to complete before making progress. Round-trips are therefore typically designed out of such protocols.
Despite the clear intent to eliminate roundtrips from network protocol design, similar issues are caused by deep stacks in a network application server that is attempting to scale to a large number of connections with high throughput, and yet running deep stacks on each CPU core is still the most common technique.
When different CPU cores are executing the same network stack layer in parallel, it is typically necessary to access the same data structures during processing. This can create unwanted lock contention on the shared data structures, further impacting performance and limiting the system’s ability to scale with additional CPU cores.
The issues highlighted above, combined with the garbage collection of so many short-lived heap objects typically created when processing the application stack, not only hinder system throughput but also lead to unwanted and unpredictable latency.
These issues become increasingly worse as the system attempts to scale.
Reaktivity
When microservices follow the shared memory streams approach defined by the Reaktivity Project, all layers of the network stack can be executed in parallel.
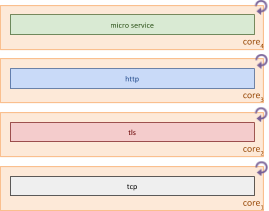
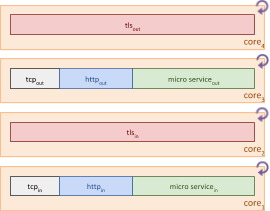
As shown in the diagram, each thread now has a distinct responsibility, using shared memory streams to communicate between the layers.
For example, the TCP layer can get back to processing the next socket read while the TLS layer is processing the previously received data. This chain reaction of parallel processing with short execution stacks reduces the amount of time between receiving data and being available to receive the next data. Throughput and latency are improved by reducing wait time for data to be processed.
The short execution stacks with predictable branching are much easier for the CPU to optimize, leading to further improvements in throughput and latency because the code for a specific layer can execute faster when optimized.
The communication between layers uses one or more bounded shared memory regions, combined with wait-free algorithms to read from and write to the shared memory. Since wait-free algorithms are both lock-free and also guaranteed to complete in a bounded number of steps, each layer can execute with predictably low latency, thus reducing the occurrence of outliers.
Each layer produces and consumes shared memory streams, with a lightweight flow control mechanism to ensure full speed execution without triggering overflow during stream processing. However, each shared memory region has a single writer, so there is no contention for memory updates on the memory bus of the underlying hardware.
Because the streams are being produced and consumed in a contiguous region of (shared) memory across different CPU cores, the underlying hardware can detect the streaming access pattern and trigger hardware prefetching of memory between those CPU cores. This hardware optimization has the effect of eliminating the wait time for data to be processed during handoff between CPU cores.
When processing the shared memory streams, each layer applies one or more reusable flyweight instances to provide structured access to the received data. This prevents unnecessary object creation and eliminates unwanted latency jitter caused by garbage collection.
However, the amount of time spent in each layer is typically not the same, so the throughput of the parallel processing is limited by the maximum time spent in any one layer.
For example, if the software-based TLS encryption and decryption dominates when compared to the other layers in the stack, then the CPU core3 would need to work harder to keep up with the other layers.
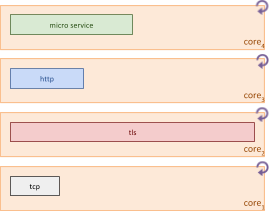
However as CPU core3 becomes fully utilized, the system reaches capacity with a suboptimal throughput due to the amount of time spent idle by the other CPU cores while waiting for CPU core3 to complete processing.
CPU core1 and core2 can be more fully utilized by shaping the workloads to combine the TCP, HTTP and microservice layers onto the same core without impacting their individual throughput, leaving CPU core3 and core4 unused.
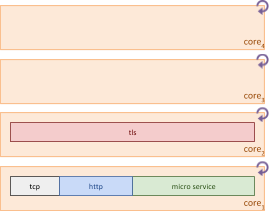
Shared memory streams are unidirectional, so we can further increase the parallelism across the remaining CPU cores by splitting the processing of input and output streams for the each bidirectional exchange, effectively doubling the capacity that could be handled when only two CPU cores were active.
In the Reaktivity Project, each layer in the network stack is a single-threaded unit called a Nukleus, and it is the Reaktor’s responsibility to assign a thread of execution to each Nukleus.
The Reaktor may choose to split a Nukleus into smaller single-threaded parts that can safely execute in parallel (fission), and it may also choose to execute some of those smaller parts on the same CPU core (fusion).
As illustrated by the Reaktive HttpServer implementation shown below, we can adapt the simple Java HttpServer API for custom microservices logic, while integrating the improved latency and throughput achieved by parallel execution of the entire application stack.
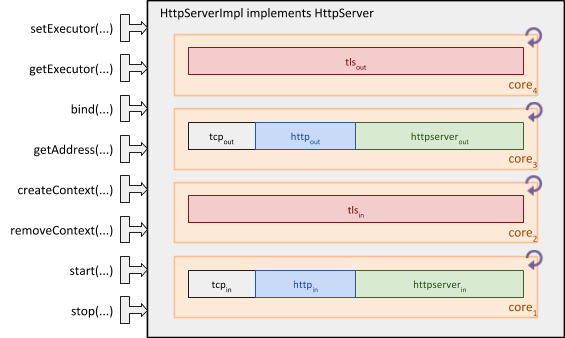
Conclusion
The Reaktivity Project can be easily adapted to existing APIs such as HttpServer to deliver high throughput microservices with predictably low latency. The Reaktor can take advantage of multiple CPU cores to deliver massive scalability by aligning with the strengths of the underlying hardware.
The formalized internal Reaktor concept of a Nukleus allows for extensibility to implement support for additional protocols or to integrate with existing systems through language-specific APIs. Even though the initial implementation targets the Java runtime environment, this architecture can be used by any language that can access shared memory, with support for Node.js coming next.
The overall design is both Docker and cloud friendly. Docker can be used to either run all Nuklei in one Reaktor on a single container, or to isolate shared memory between multiple containers running different Reaktors on the same host. The linear scalability obtained by running additional Reaktors on peer hosts lends itself to elastic auto-scaling in the cloud.
Typically, system performance can degrade significantly when verbose logging is enabled to diagnose runtime behavior. However, the shared memory used to communicate between Nuklei is the equivalent of a binary trace level log and is effectively always switched on. Therefore, shared memory streams can be observed passively from a different CPU core for logging and diagnostics purposes with no performance impact.
The Reaktivity Project provides developers with a “fast start” that will maximize their productivity to create high throughput microservices with predictably low latency.